Statistical inference on Histogram#
In this tutorial, we will generate a mock histogram and see if our signal model is good enough to explain the experimental data.
Let us generate a histogram to be used in our example first. In below example, we generate three sets of data, signal (\(n_s\)), background (\(n_b\)) and observarions (\(n\)). The statistical uncertainties on the background yields are shown with black lines.

Lets construct a statistical model. Since the only source of uncertainty is statistical, we can safely assume that non of the bins are correlated in systematic level. Hence we will use "default.uncorrelated_background" model.
pdf_wrapper = spey.get_backend("default.uncorrelated_background")
stat_model = pdf_wrapper(
signal_yields=s_and_b - b_only,
background_yields=b_only,
data=data,
absolute_uncertainties=np.sqrt(b_only),
)
Now we can compute the normalised likelihood distribution for prefit and postfit statistical models.
poi = np.linspace(-0.3, 8, 50)
llhd_postfit = [stat_model.likelihood(p, return_nll=False) for p in poi]
muhat_postfit, max_llhd_postfit = stat_model.maximize_likelihood(return_nll=False)
llhd_prefit = [
stat_model.likelihood(p, expected=spey.ExpectationType.apriori, return_nll=False)
for p in poi
]
muhat_prefit, max_llhd_prefit = stat_model.maximize_likelihood(
expected=spey.ExpectationType.apriori, return_nll=False
)

Now let us compute the expected and observed upper limits on signal strength (\(\mu\)) at 95% CL:
print(f"Observed upper limit on µ at 95% CL: {stat_model.poi_upper_limit():.5f}")
expected_pval = stat_model.poi_upper_limit(
expected=spey.ExpectationType.aposteriori, expected_pvalue="1sigma"
)
muUL_apost = expected_pval[1]
print(
"Expected upper limit on µ with ± 1σ at 95% CL: "
+ ",".join([f"{x:.3f}" for x in expected_pval])
)
Observed upper limit on µ at 95% CL: 4.66815
Expected upper limit on µ with ± 1σ at 95% CL: 2.834,3.764,5.183
We can use confidence_level flag to change the confidence level of our calculation
print(
f"Observed upper limit on µ at 68% CL: {stat_model.poi_upper_limit(confidence_level=0.68):.5f}"
)
Observed upper limit on µ at 68% CL: 2.79069
Now let us compute the upper limit by hand:
poi = np.linspace(1, 7, 20)
poiUL = np.array(
[
stat_model.exclusion_confidence_level(
poi_test=p, expected=spey.ExpectationType.aposteriori
)
for p in poi
]
)
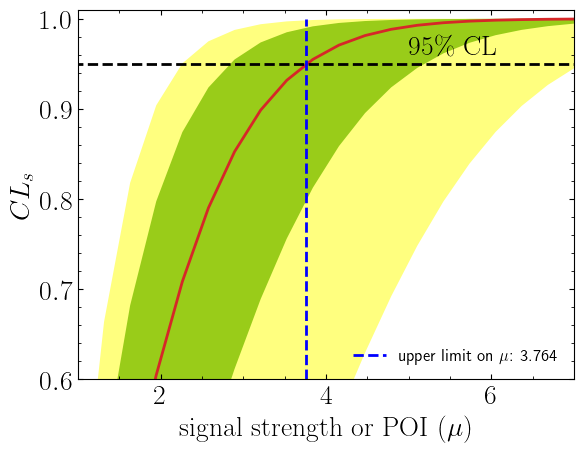
Additionally we can compute the exclusion limit of our signal model to see if our model is excluded.
print(
f"Observed exclusion confidence level, CLs: {stat_model.exclusion_confidence_level()[0]:.5f}"
)
exp_cls = stat_model.exclusion_confidence_level(expected=spey.ExpectationType.aposteriori)
print(
f"Expected exclusion confidence level, CLs ± 1σ: {exp_cls[2]:.4f} - {exp_cls[2]-exp_cls[3]:.4f} + {exp_cls[1]-exp_cls[2]:.4f}"
)
Observed exclusion confidence level, CLs: 0.13942
Expected exclusion confidence level, CLs ± 1σ: 0.1620 - 0.0972 + 0.1182
Since our model is not excluded (\(1-{\rm CL}_s < 0.95\)), we may want to see the significance of our signal yields:
print(f"Z = {stat_model.significance()[1]:.3f}")
Z = 1.185